Наборы символов HTML
Наборы символов HTML — ASCII, ANSI, ISO-8859-1 и UTF-8 — и объявление кодировки через мета-тег charset для корректного отображения страниц.
Набор символов (или кодировка символов) — это соответствие, которое указывает браузеру, как преобразовать необработанные байты файла в буквы, цифры, знаки препинания и символы, отображаемые на экране. Браузер должен знать, какую кодировку использует страница, чтобы правильно её отобразить.
UTF-8 — кодировка символов по умолчанию для HTML5. Так было не всегда. Первым появился ASCII, а ISO-8859-1 был кодировкой по умолчанию с HTML 2.0 до HTML 4.01. Каждый из этих старых наборов мог представлять лишь ограниченный диапазон символов, что создавало проблемы с текстом на неанглийских языках. Когда вместе с HTML5 и XML появился UTF-8, он решил большинство этих проблем, охватив в одной кодировке практически все письменности мира.
На этой странице рассматриваются основные наборы символов, с которыми вы можете столкнуться, — ASCII, ANSI, ISO-8859-1 и Unicode/UTF-8 — и показано, как объявить кодировку в современном и устаревшем HTML.
Что происходит при отсутствии или несоответствии кодировки
Если страница не объявляет кодировку или объявляет не ту, с которой файл был фактически сохранён, браузер угадывает — и зачастую угадывает неверно. Наиболее распространённый симптом — мусорные символы (мокибаке): искажённый текст, в котором буквы с диакритиками, типографские кавычки или эмодзи превращаются в строки вида é или ’.
Помимо визуальных искажений, необъявленная или несоответствующая кодировка может представлять угрозу безопасности: некоторые атаки основаны на том, что браузер интерпретирует байты в кодировке, отличной от задуманной автором (например, межсайтовые скрипты на основе UTF-7). Явное указание единственной кодировки устраняет эту неоднозначность. Безопасный современный выбор — всегда отдавать контент в UTF-8 и явно заявлять об этом с помощью <meta charset="UTF-8">.
ASCII
ASCII был первым стандартом кодировки символов, который также называют набором символов. Аббревиатура расшифровывается как American Standard Code for Information Interchange.
Для каждого сохраняемого символа ASCII определял уникальное число, поддерживая прописные и строчные буквы алфавита (a-z, A-Z), цифры 0-9 и небольшой набор специальных символов. Он основан на английском алфавите и кодирует 128 символов в 7-битное двоичное целое число. Например, заглавная буква A имеет код 65 (двоичный 01000001), a — 97, а цифра 0 — 48. Это работает потому, что вся компьютерная информация в конечном счёте записывается в электронике в виде двоичных единиц и нулей.
Ниже представлена таблица ASCII, сопоставляющая каждый символ с его десятичным, шестнадцатеричным и двоичным кодом.
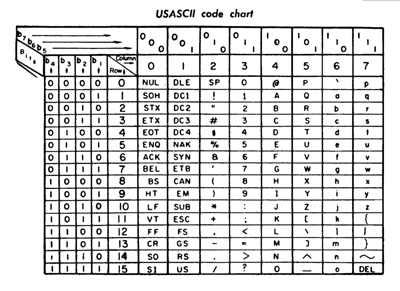
Главное ограничение ASCII — отсутствие неанглийских букв и символов с диакритиками. Он до сих пор используется, особенно на мейнфреймах, и служит фундаментом, на котором строятся последующие кодировки (в том числе UTF-8).
Нажмите здесь, чтобы узнать больше об ASCII.
ANSI
ANSI, также известный как Windows-1252, был кодировкой по умолчанию для Windows вплоть до Windows 95. Это расширение ASCII с добавлением международных символов. Он поддерживал 256 символов, используя полный байт (8 бит).
ANSI поддерживался всеми браузерами, поскольку был объявлен кодировкой по умолчанию для Windows.
ISO-8859-1
ISO-8859-1 стал кодировкой по умолчанию в HTML 2.0, поскольку большинство стран используют символы, отличные от ASCII. Это также расширение ASCII, как и ANSI, с добавлением международных символов. ISO-8859-1 также использует полный байт, что позволяет представить вдвое больше символов, чем ASCII.
Нажмите здесь, чтобы узнать больше об ISO-8859-1.
Кодировка по умолчанию в HTML 4
В HTML 4 кодировка объявлялась с помощью тега <meta> с атрибутом http-equiv. Поскольку ISO-8859-1 была кодировкой по умолчанию, её явное указание выглядело так:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />Переопределение кодировки в HTML 4
Если странице HTML 4 нужна кодировка, отличная от ISO-8859-1 по умолчанию, — например ISO-8859-8 для иврита, — достаточно изменить значение charset в том же теге <meta>:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8" />Большинство процессоров HTML 4 также понимали UTF-8, что проложило путь к его становлению стандартом в HTML5.
Способ HTML5
HTML5 заменил подробную форму с http-equiv коротким специализированным атрибутом:
<meta charset="UTF-8" />Размещайте этот тег как можно раньше внутри элемента <head> — в идеале самым первым дочерним элементом, — чтобы браузер прочитал кодировку прежде, чем начнёт разбирать текстовое содержимое.
Unicode UTF-8
UTF-8 — кодировка по умолчанию и рекомендуемая для HTML5.
Поскольку описанные выше наборы символов ограничены максимум 256 символами, Консорциум Unicode разработал Стандарт Unicode — единый каталог, присваивающий уникальный номер (называемый кодовой точкой) почти каждому символу, знаку препинания и обозначению, используемому в мире, — в тысячах языков, включая эмодзи и математические символы. UTF-8 — наиболее популярный способ кодирования этих кодовых точек в байты.
Почему UTF-8 является современным стандартом
Три свойства делают UTF-8 естественным выбором для веба:
- Универсальное покрытие. Он может представлять каждую кодовую точку Unicode, поэтому одна страница может сочетать английский, арабский, китайский и эмодзи без смены кодировки.
- Совместимость с ASCII. Первые 128 кодовых точек кодируются точно теми же однобайтовыми значениями, что и в ASCII. Любой простой ASCII-файл уже является допустимым UTF-8, а значит, десятилетия старых текстов и инструментов продолжают работать.
- Эффективность переменной ширины. Распространённые символы занимают всего один байт, а менее распространённые используют два, три или четыре байта только при необходимости. Документы, состоящие преимущественно из английского текста, остаются компактными, и при этом ничего не упускается.
В HTML атрибут charset тега <meta> указывает кодировку:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>UTF-8 example</title>
</head>
<body>
<p>English, Русский, 中文, العربية, 😀</p>
</body>
</html>Держите <meta charset="UTF-8"> первым элементом в <head> (в пределах первых 1024 байт документа). Если он появится слишком поздно, браузер может начать разбирать текст в неправильной кодировке до того, как увидит объявление.
Многобайтовые символы и BOM
В UTF-8 один символ может занимать несколько байт. Например, знак евро € (кодовая точка Unicode U+20AC) хранится как три байта E2 82 AC, тогда как такой символ, как A, по-прежнему занимает только один байт. Именно это на практике означает «переменная ширина».
Вы также можете встретить BOM (метку порядка байтов) — необязательную невидимую последовательность байтов (EF BB BF для UTF-8) в самом начале файла, сигнализирующую о его кодировке. BOM не требуется для UTF-8 и в HTML обычно лучше его опускать, поскольку явный тег <meta charset="UTF-8"> уже выполняет эту задачу, а лишний BOM может иногда вызывать проблемы с отображением.
Чтобы вставить конкретные символы, не беспокоясь о том, как редактор сохраняет файл, можно также использовать именованные или числовые HTML-сущности (например € для €).
Все процессоры HTML5 поддерживают UTF-8. Обратите внимание, что процессоры XML строго требуют UTF-8 или UTF-16.